Prose_统计暨编程问题日志
本文简记日常遇到的统计暨编程问题。为便于查阅,日志按倒序排列,分统计问题日志与编程问题日志两部分。分统计基础、R、Python、Stata、Others五类日志,廿四年六月。另,补充我以为有趣的“日常生活中的统计学”日志,廿五年八月。
一、统计问题日志
2024.9.13 Wilmoth(2012)的K值含义
晚上Siyao问我怎么修小群体的预期寿命,通过大区的e0与45q15可以估计一个地区的K值,然后用这个K值与小群体45q15可以估计e0。怎么理解这个k值?
我认为K值调整的是死亡率曲线的形状,决定了不同年龄段之间死亡率的分布形态,具体讲,k就是成人死亡率相对于默认曲线的偏离,如果 k > 0,就是成人死亡率相对于通过儿童死亡率(5q0)估算出的典型模式要更高,k < 0,就是曲线在成人阶段会下降。另一个参数45q15则相当于一个死亡水平的锚点。如果A群体的健康转变滞后于B群体,那么合理的猜测是A的k要大于B的k。此外,基于HMD的估计,因为数据从19世纪一直到21世纪,所以其5q0得到的经典表大约是1950年代左右。我看了下中国1950年代的k值也基本是0.+,很符合预期。
2024.8.10 人口学家在健康不平等
标记几个健康不平等领域的人口学家,持续关注。
| Demographer | Nation | University |
|---|---|---|
| Iñaki Permanyer | Spain | Autonomous University of Barcelona |
| Vladimir Canudas Romo | AUS | Australian National University |
| Jiaxin Shi | CN / US | Max Planck Institute |
| Mengxue Chen | CN / AUS | Australian National University |
2024.6.15 死因数据集及其历史
2024.5.19 R 人口学博客
简录几个人口学家博客,他们提供了很多可使用的R代码。原载于2022.3.31 日记。
| Demographer | Nation | University |
|---|---|---|
| Eddie Hunsinger | US | Esri’s Data Development team |
| Germán Rodríguez | US | Princeton University |
| Guy Abel | UK | The University of Hong Kong |
| Dudel Christian | German | Max Planck Institute |
| Minato Nakazawa | Japan | Kobe University |
2024.5.9 R 贝叶斯预测
今天北大开家庭和居住安排预测会,我太困了没去。自颖帮我记了一下会议中提到的贝叶斯预测R包,如BayesProj、bayesTFR、bayesLife、bayesPop等。
2023.3.28 Stata 非线性交互项的MAE方法
Probit交互项是不可以直接进行比较的,洪岩璧15年即有一篇《社会》上的文章有讨论。按Jiang Chun-Yun的建议,张扬老师曾在组会分享了其最近在European Sociological Review使用的方法,即普度Trenton D.等人19年在Sociological Methodology开发的边际效应比较(Marginal Effects Comparison)方法,其STATA代码可见mecompare。
2022.12.27 IV-Probit Wald Test问题
参见"Anderson-Rubin test in IVprobit using weakiv"与"ivprobit test of instrument strength"两篇帖子的回答,Wooldridge谈了ivprobit的iv检验可以直接看reg计算的estat first结果,如果显著,再使用ivprobit估计得到的系数。
2022.11.18 Beta收敛模型正负向问题
最近一段时间做贝塔收敛,各个论文里使用的公式都不一致,本质是大家不严谨,核对了一下Barro和Sala-I-Martin的原文,他们对beta系数使用了一个trick变换正负号,把越小越收敛,改为越大越收敛。
2022.7.1 Stata 加权中dev与err区别
宛莹询问加权描述中,输出std dev与std err的区别,可参照如下两个回答。简言之,std err是针对样本均值的区间,std dev是单个值相对于样本均值的离散,加权描述时汇报哪个都可以。《Standard Error of the Mean v.s. Standard Deviation: What’s the Difference?》、《How can I calculate the standard deviation with weight?》
svyset [pweight= weight]
svy: mean a1 a2 a3
estat sd
2022.3.30 R Life Table Model
最近做模型生命表,简录一些人口学方面的R包信息。
第一是Lifetables包,这个包做Clark-Sharrow(2012)表。其问题是没有更新配套的说明论文。国内有一篇2012年武大公卫胡松波的博论介绍,停留在Clark 2012那篇的5种死亡模式的划分,这个老版本已经下架了,实际上Clark的合作者Sharrowclark在2015年基于其2013博论与2015 HDS数据进行了修订,目前可以直接官网install的这个包实际有7种死亡模式。所以实际应该为Clark-Sharrow(2015)表。
第二是svdComp5q0包,这个包做Clark(2019)表。这个包是Clark 2019年对Clark-Sharrow(2015)的改进升级。
第三是MortalityEstimate包,这个包做Wilmoth(2012)表,其他替代包如MortCastb包logquad函数; 或DemoTools包,但是更推荐MortalityEstimate。DemoTools包做简略生命表的1岁组展开比较好用。
第四是Murray表,建议直接使用Rodríguez提供的函数,或Stata统计软件的软件包Modmatch,这个包已经不能直接安装,且只能在老Stata版本里使用。
第五是一些其他方法的包,如DDM, SUMMER等,可以做贝叶斯等模型。
此外,一些基础生命表函数,推荐使用Eddie Hunsinger的Applied Demography Toolbox,他基于Stanford Workshop改了一个单岁组的R程序,另如如Stanford生物人类学James Holland Jones写了一个demogR包,其life.table函数在1岁组有问题,nax值即便指定1岁组也未更新,即是说nax在1岁时值是1.5左右,虽然Jones其实也是改的Stanford Workshop的程序。平滑5岁组至1岁组的死亡率,则推荐使用ungroup包,已在多个流病和人口学论文中应用。
2022.2.6 普查性别比问题
最近徐州八孩案,或可论及宏观性别比与微观性别平等观念的关联。但如网友扒出来的2000年丰县婴儿出生性别达160,其实县一级出生人口未公布,公布的普查长表是1%抽样,除去漏报假设有20%,一个县1%,可能仅有5、6个出生孩子,依据此计算的出生性别会非常不稳健。当然,泛淮海的传统确根深蒂固,我对社会如此感到厌倦。
2022.1.9 回归分析常见误区
参《回归分析的几个常见误区》一文。
2021.12.18 LCA与LPA
经查阅,LCA与LPA的区别如下。
| 潜变量 | 外显变量 | 外显变量 |
|---|---|---|
| 类别 | 连续 | |
| 类别 | 潜在类别分析(Latent Class Analysis) | 潜在剖面分析(Lantent Profile Analysis) |
| 连续 | 潜在特质分析/项目反应理论(Latent Trait Analysis) | 因子分析(Factor Analysis) |
2021.11.18 HAPC
下午听林宗宏的《跨期资料分析:时期、世代与模型选择》,他以台湾社会变迁为案例。
林概述了CCREM模型(随机效应虚拟变量)、CCFEM模型(固定效应虚拟变量)的应用。他面询了Lund,对于模型的使用,有如下建议:
第一,使用CCREM至少需有五期以上的数据,最好是七期以上;否则,当只有三期以下合并数据时,使用HLM或固定效应的时期虚拟变量;
第二,在4~7期之间可以使用CCFEM或CCREM,看两者的统计差异是否非常显著(Ken Land),如果APC效果很不稳定或考虑放弃讨论世代议题,用时期与其他变量的交互作用来呈现社会变迁;
第三,在数据处理上,寻找长期(定期)连贯的变量,有许多问题都乏人问津(宗教/家庭价值观);在最终模型里尽量不要依各期切割样本:(a)可以保持样本的总量、(b)有助于跨时段比较;
第四,当年龄与世代不是关注重点时,不必轻易动用CCREM,建议使用连续变量控制A与P,或以固定效应控制A,以HLM控制P效果
第五,宏观统计资料可以引入,当成层级资料或个体资料使用。
2020.11.12 拟合度检验
有同学问我拟合度检验(Goodness of Fit)与Hosmer-Lemeshow检验的问题,我之前没有仔细考虑过,自己也很糊涂,有时间会专门写一篇文章进行梳理。查阅到关于HL检验的问题,P Allison曾专门写过Why I Don’t Trust the Hosmer-Lemeshow Test for Logistic Regression较有帮助。我简要整理为另文。
2020.8.29 RIF分解
看了一篇文章,查阅了RIF方法,其原理可参考再中心化影响函数RIF回归和分解的Stata操作程序,实操方法可参考RIF regression and RIF decomposition following Heckley’s methodology。更具体的统计原理可参考朱平芳与张征宇(2012)《统计研究》的文章《无条件分位数回归:文献综述与应用实例》。
(1)自从Koenker和Bassett(1978)提出分位数回归(Quantile Regression, QR)方法以来,其已发展成为经济学实证研究的常用方法之一。最初,QR方法仅被看作是用来替代最小二乘(OLS)估计的一种稳健(robust)估计。但基于微观数据的研究中青睐QR方法,并不在于它的稳健特性,而是可以借此方法了解解释变量对于被解释变量在扰动项的不同分位点上的异质性影响。通常,人们在评估一项经济政策对受众群体的影响时,不但希望了解政策对任一参与者的平均影响,更希望知道政策对位于特征分布不同位置(分布末端或顶端)人群的异质性作用。
(2)条件分位数(CQR)方法的结果,实际上只告诉我们对于具有相同观测特征的个人(例如,具有某一特定年龄、家庭背景的女性),不可观测的“能力差异”对于“收入”的异质性影响。
(3)但由于CQR的经济学意义阐释基于过多甚至是不必要的个体特征,其结果与政策制定者所关心的问题很有可能并不一致。例如,人们可能只想了解教育年限对于个人收入的一般边际影响,而无论个体的年龄,性别与家庭背景如何,这就是所谓收入关于教育程度的无条件分位数估计问题。
2019.9.2 DiD的原理
| 政策实施前 | 政策实施后 | Difference | |
|---|---|---|---|
| 实验组 | |||
| 对照组 | |||
| Difference |
2019.9.1 两样本合并后均值与标准差
| 组1 | 组2 | 合并组 | |
|---|---|---|---|
| 样本量 | |||
| 均值 | |||
| 标准差 |
下面我简要地推导这一标准差公式如何得到。
设
则
二、R问题日志
2024.5.6 R Mac升级
检查了一下R版本,已经更新到4.4,我之前是直接在官网download的R,包的迁移很麻烦。对于Mac,便捷的方法是使用brew管理。
brew install r --cask # 不要使用brew install r,配置路径会很麻烦
mv /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources
sudo chown -R $USER /Library/Frameworks/R.framework/Versions #如没有权限可以放开权限
installed.packages()
update.packages()
brew upgrade r --cask
2021.12.22 R LDAvis包输出空白问题
R语言LDAvis输出json后,需要授权浏览器读取本地文件,Mac系统可以在bash输入,再读取html文件。这个问题其实很简单,但是csdn、知乎很多网站都没有说明,反而误导人以为是R包问题。
open -a "Google Chrome" --args --allow-file-access-from-files
2021.10.21 R rattle包安装失败日志
首先,在R端安装失败。
# The First Try.
# Try to take the action below, but failed.
install.packages("gWidgets", repos="https://R-Forge.R-project.org")
install.packages("rattle")
install.packages("RGtk2") #can't install, need to install X11 and GTK+
其次,按XQuartz(X11)、GTK+ 2.24.17(X11)两篇文章配置X11、GTK+后,R端仍无法安装RGtk2包。
install.packages("RGtk2", depen=T, type="source")
# Still had non-zero exit status, error is GTK version 2.8.0 required, restall GTK3+.
再次,因报错GTK需要2.8以上版本,按《MacOSX下配置GTK开发环境》,在bash端brew升级。
# The Second Try.
brew install pkg-config #cmd
brew install gtk+3 #very slow, about 1 hour in china mainland.
pkg-config --list-all |grep gtk # find version
尔后,在CRan_RGtk2_2.20.36.2.tgz下载包,本地可以安装,但无法连接rattle包的GTK路径。
install.packages("~/Downloads/RGtk2_2.20.36.2.tgz", repos = NULL, type = .Platform$pkgType)
library(rattle);rattle()
# Still error, "R_gtkInit" not available for .C() for package "RGtk2"
最后,按《無法安裝rattle至MacOsx系統》、《『R studio』如何在Mac OS系統上建立rattle》两文继续尝试,未果。初步怀疑为M1芯片不支持。
install.packages(c("RGtk2", "cairoDevice"), repos = "https://giesrbt.github.io/repo-r")
# Still error, and other answers may help, but i tired to try.
# https://zhiyzuo.github.io/installation-rattle/
# https://bda2020.wordpress.com/2018/04/05/installing-rattle-on-mac/
# But I guess its caused by M1 core, and I give up this package.
2021.10.13 R reticulate包
按Wrong Architecture on M1 chip (R 4.1.0 ARM),M1 based R疑似无法调用reticulate包。补记,由于anaconda目前仅支持x86,完全卸载后安装miniforge3 arm64即可,但Python 3.6 is not available on M1。
2021.9.26 R rmarkdown包
上午参照《TinyTeX 中文文档》、《Rmarkdown中文实现》配置了rmarkdown。
2020.9.2 R rJava
中午调试rJava,尝试了网上的各种办法,包括但不限于:(1)macOS内Java管理、(2)重装低版本Java 8的JDK和JRE、(3)修改/.bash_profile并sudo R CMD javareconf、(4)升级R从4.00至4.02等各种办法。折腾到下午三点多均无效。后按看过的一篇文章重新做了一遍起效。应该是“连接libjvm.dylib to /usr/local/lib:”这一步出了问题。错误如下:
Error: package or namespace load failed for ‘rJava’:
.onLoad failed in loadNamespace() for 'rJava', details:
call: dyn.load(file, DLLpath = DLLpath, ...)
error: unable to load shared object '/Library/Frameworks/R.framework/.../rJava/libs/rJava.so':
dlopen(/Library/Frameworks/R.framework/.../rJava/libs/rJava.so, 6):
Symbol not found: _EXTPTR_PTR
Referenced from: /Library/Frameworks/R.framework/.../rJava/libs/rJava.so
Expected in: /Library/Frameworks/R.framework/Resources/lib/libR.dylib
in /Library/Frameworks/R.framework/Versions/4.0/Resources/library/rJava/libs/rJava.so
三、Python问题日志
2022.7.9 Py Peddlehub库
昨日调用百度飞桨NLP库,报错ONNX fails to install on Apple M1.,安装如下程序解决:
brew install cmake
brew install protobuf
pip3 install onnx --no-use-pep517
今日调用飞桨hub框架出现“libprotobuf ERROR google/protobuf/descriptor_database.cc”的报错,排查认为是py3.10更新了module ‘collections’ has no attribute ‘MutableMapping’,删除3.10环境后,安装3.9环境后正常。
另,昨日在py3.9环境下调用百度的nlp api会报错,python3.10下无异常,因后弃用该代理api分析所以没有继续跟踪该问题。
2022.7.8 Py scrapy报错
问题描述:使用Weibo-search爬虫包,但scrapy库报错MemoryError,排查认为python3.9使用的requests库调用pyopenssl报错。
问题伴随SSL认证失败,经查资料:根据MemoryError: Cannot allocate,初步确定是pyopenssl,openssl有写和执行权限,而pyopenssl则没有。但是Scrapy依赖pyopenssl。——安装Scrapy出现报错
解决方法:创建环境python3.10并改用pip install Scrapy,注意,py310通过conda install Scrapy途径会报错,未知原因。
此外,中间出现一个问题是conda install因报错内存占满而失效,各种尝试无果后删除miniforge3的conda,恰好看到《M1 Mac安装原生Anaconda3》,遂重新安装M1 anaconda。
2021.10.28 Py 配置nltk库
下午在py3.6下配置了nltk与tensorflow,nltk包数据需科学上网。
2021.9.20 Py Jupyter Notebook插件
下午在寝室配置了jupyter notebook的插件环境。按《Jupiter Notebook扩展插件的安装及推荐》配置jupyter notebook插件,并配置了Table of Contents,如下:
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
#The code blew is only required if you have not enabled the ipywidgets nbextension yet.
#jupyter nbextension enable --py --sys-prefix widgetsnbextensionpip install qgrid`
jupyter nbextension enable --py --sys-prefix qgrid
并按《jupyter notebook自动补全功能实现》配置了排版工具Autopep8与自动补全工具Hinterland,hinterland由于版本问题,降级参考了《解决jupyter notebook勾选hinterland后代码不能自动补全问题》。
pip install Autopep8
pip install -U jedi==0.17.2 parso==0.7.1
pip install ipython==7.10.0
2021.9.17 Py3.6 jupyter与pyhanlp库
下午升级了hanlp后,昨日的配置出了问题。想了想是因为NLP课件中的pyhanlp是基于java的,版本是1.x;hanlp是基于py的,版本是2.x。且py3.6通过conda安装jupyter notebook会导致kernal无法连接,因此,在安装py3.6虚拟环境下的pyhanlp时,完整流程如下:
conda create --name py36 python=3.6 anaconda #配置3.6环境
conda activate py36 #激活3.6
pip install jupyter notebook #必须通过pip安装notebook,conda安装则无法连接
conda install -c conda-forge openjdk python=3.6 jpype1=0.7.0 -y #安装hanlp依赖java环境
pip install pyhanlp #安装pyhanlp
hanlp #初次使用需下载hanlp语料库
2021.9.16 Py3.8 hanlp库
下午听了信息学院蒋老师的《python与自然语言处理》,按《修改Jupyter默认目录》、pyhanlp项目主页配置了NLP环境。
四、Stata 问题日志
2023.10.27 Stata DDML
DDML需要调用python的scikit-learn库(pystacked),需要指定python的路径,同时M1芯片需要注意conda的芯片版本是否适用。查找py路径参考网页。
which python
*/usr/local/bin/python
ls -al /usr/local/bin/python
python search
python set userpath path [path ...] [, permanently prepend]
python set exec pyexecutable [, permanently]
2019.3.19 Stata Heise系数集束化
系数集束化(Sheaf Coefficients)是Heise创立的一种后估计方法,这种方法得出的系数集束是一系列变量通过一个潜在变量对因变量的影响。这种估计不是检验的,只是模型中呈现结果的不同方式。这种方法主要的作用是比较一系列变量的相对影响强度。这种相对影响强度是经过标准化处理的,标准差都是1,所以可以直接进行比较(梁玉成,2019)。
关于系数集束化,我们可以简单举个例子,比如检验哪些因素影响家庭住房面积?可能有人力资本、政治资本的影响,但是这两个资本有很多测量方法,我们如何简单明了的展示呢?这时便可以使用系数集束化方法,代码如下。
** model1 human captial
quietly reg lnhouse faincome edu age sex householdnum marriage property1 property2 urban
** heise
sheafcoef, latent(human_capital: faincome edu) post
outreg2 using example.docx, replace
** model2 political captial
quietly reg lnhouse faincome edu danwei2 party age sex householdnum marriage property1 property2 urban
** heise
sheafcoef, latent(human_capital: faincome edu; political_capital: danwei2 party) post
outreg2 using example.docx
** test
estat hettest, rhs iid
estat vif
五、Others日志
2026.3.15 更新本地软件
整理本地开源软件,列下:Battery、Mac mouse fix 2、Maccy、LaunchNext、LocalSend、HandBrake、iTerm2、CotEditor、Easydict、Ice、Lulu、Amphetamine、IINA、Motrix等。另,按《RIME中州韵输入法词库扩充》迁移了搜狗输入法,重新部署鼠须管,弃用薄荷或雾凇,转用万象。
sudo spctl --master-disable
sudo xattr -cr /Applications/深蓝词库转换-arm64.app # 搜狗输入法词库迁移
2026.3.14 模型本地部署
按查阅《本地安装开源大模型最新王者 Qwen3.5》,部署了最新大模型。我认为今年可以算是本地大模型元年了,两年之内每个手机、电脑都会有本地大模型,我们已迎来手机的iPhone时刻。补记,测试了qwen2.5,质量差距过于明显。
# brew install ollama
ollama pull qwen3.5:9b
ollama pull qwen3.5:27b
# ollama pull modelscope.cn/unsloth/Qwen3.5-9B-GGUF
ollama run qwen3.5
ollama stop qwen3.5
另附测试结果(输入test)。按量化int4、8k context length,M5 24g显示,qwen3.5的9b非常丝滑、27b有较大延迟。怀疑 Ollama + GGUF对M芯片的优化有限,可能换成MLX会好一些?基于LLM的社科仿真已具备在本地模拟的条件。
ollama run qwen3.5:9b --verbose
<!-- total duration: 1.578392459s
load duration: 103.127917ms
prompt eval count: 13 token(s)
prompt eval duration: 308.105167ms
prompt eval rate: 42.19 tokens/s
eval count: 21 token(s)
eval duration: 1.147118751s
eval rate: 18.31 tokens/s -->
ollama run qwen3.5:27b --verbose
<!-- total duration: 1m6.160082416s
load duration: 109.015ms
prompt eval count: 11 token(s)
prompt eval duration: 41.160034458s
prompt eval rate: 0.27 tokens/s
eval count: 110 token(s)
eval duration: 24.81666013s
eval rate: 4.43 tokens/s -->
2024.8.20 Bash Markdown to Word, pandoc
在markdown里写LaTex公式后,如何便捷将公式转为word格式?使用pandoc
brew install pandoc
cd ~/desktop/test
ls
pandoc abc.md -f markdown -t docx -s -o abc.docx
2024.5.27 Bash Mac m4a/mp4 to mp3
brew install ffmpeg
cd ~/downloads
ffmpeg -i input.m4a -c:v copy -c:a libmp3lame -q:a 4 output.mp3
ffmpeg -i input.mp4 input.mp3
2024.5.26 Bash 批量替换文件内容
Mac中使用bash批量替换内容。
for file in xxx/xxx/*.md; do sed -i '' 's/\*\*\*/\*/g' "$file"; done
2024.4.13 Git lft
因往github更新旅行地图,使用git lfs上传超100mb地图文件。
brew install git-lfs
cd ~/Documents/0_Academic_Road/0_CV/Blog_Slides
git lfs install
git lfs track "Travel_Map/Map_Geo.RData"
git add .gitattributes
git add .
git add Travel_Map/Map_Geo.RData
git commit -m “add map_geo”
git push origin main --force
2023.12.12 Software Safari Readling list trans to bookmarks
如何将safari的reading list 转换为bookmark的一个分类,我在网上没有看到很好的办法,这里给出一个便捷的转换流程。
- python将safari rl导出
- 将json转换为html格式
- 将html读入谷歌浏览器并导出
- 再次导入safari
- 此外,如存在较多bookmark(比如我有1500+),可以用谷歌插件Bookmarks clean up进行去重和失效网页查询
2023.9.18 Bash 单文本转utf-8
iconv -f GBK -t UTF-8 ~/desktop/text1.txt > ~/desktop/text2.txt
2023.6.4 Software & Py 批量替换文件内容
该方法过于麻烦,已废弃。
import os
import re
import time
def modify_md_content(top):
for root, dirs, files in os.walk(top, topdown=False):
# 循环文件
for file_name in files:
file_name_split = file_name.split('.')
try:
if file_name_split[-1] == 'md':
# 找到md文件且复制md文件路径
md_file_path = os.path.join(root, '.'.join(file_name_split))
copy_md_file_path = os.path.join(root, '.'.join([f'{file_name_split[0]}_copy', file_name_split[1]]))
# 打开md文件进行替换
with open(md_file_path, 'r', encoding='utf8') as fr, \
open(copy_md_file_path, 'w', encoding='utf8') as fw:
data = fr.read()
data = re.sub(' - Politics', ' - Politics & Political Philosophy', data) # 替换内容
fw.write(data) # 新文件一次性写入原文件内容
# 删除原文件
os.remove(md_file_path)
# 重命名新文件名为原文件名
os.rename(copy_md_file_path, md_file_path)
print(f'{md_file_path} done...')
time.sleep(0.5)
except FileNotFoundError as e:
print(e)
time.sleep(0.5)
if __name__ == '__main__':
top = r'/Users/yuteng/Desktop/_posts'
modify_md_content(top)
2023.3.31 Software Zotero期刊大写
改了一个已有的Javascript 程序,使zotero的期刊统一首字母大写。
var items = ZoteroPane.getSelectedItems();
var n = 0;
for (item of items) {
var publication = item.getField('publicationTitle');
new_publication = titleCase(publication). // 转换为单词首字母大写
replace('And', 'and'). // 替换And
replace('For', 'for'). // 替换For
replace('In', 'in'). // 替换In
replace('Of', 'of'). // 替换Of
replace('With', 'with').
replace('Usa', 'USA').
replace('Dna', 'DNA').
replace('Pcr', 'PCR').
replace('Ros', 'ROS').
replace('To', 'to')
item.setField('publicationTitle', new_publication);
await item.saveTx();
n ++
};
return n + '个条目的题目大小写转为词首字母大写,有些特殊缩写单词可能转换错误。';
// 将单词转为首字母大写
function titleCase(str) {
var newStr = str.split(" ");
for(var i = 0; i < newStr.length; i++) {
newStr[i] = newStr[i].slice(0,1).toUpperCase() + newStr[i].slice(1).toLowerCase();
}
return newStr.join(" ");
};
2023.3.28 Software GPT3.5部署
最近Chatgpt火热,上午听完上海大学的GPT社会学意义讲座后,在Github找到了一个网页App,凑热闹部署了一个自用版的。
2022.5.1 Software & Py Zotero处理tags
zotero批量删除tags尚没有合适的插件,可以使用pyzotero处理,参我在zotero的回答。
2022.4.22 Git 常用命令
按《使用git上传代码到Github》、《Git全局配置忽略.DS_Store》两文配置github,另按《Git清除历史记录》清除.DS_Store文件删除记录。
又及《git将本地文件推送到远程仓库》、《git中push出现Everything up-to-date》总结git流程。
# 初始化
git init
# 建立本地与远端连接,推荐ssh连接
git remote add origin https://github.com/username/projectname.git
git remote set-url origin git@github.com:username/projectname.git
# 远端下拉
git pull origin https://github.com/username/projectname.git
# 添加暂存区与本地仓库
git add .
git commit -m "test"
# 传输远端项目
git push -u origin main
2022.4.21 Bash 配置item2
注意,使用zsh后原路径如nvm、npm、conda等需重新配置。具体而:第一,安装oh-my-zsh需科学上网;
export https_proxy=https://127.0.0.1:7890 http_proxy=https://127.0.0.1:7890 all_proxy=socks5://127.0.0.1:789
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
第二,安装highlighting与autosuggestions插件。
brew install zsh-syntax-highlighting
brew install zsh-autosuggestions
source /opt/homebrew/share/zsh-syntax-highlighting/zsh-syntax-highlighting.zsh
source /opt/homebrew/share/zsh-autosuggestions/zsh-autosuggestions.zsh
2022.2.24 Excel 无格式文本粘贴宏
启用宏,命令如下:
Sub paste()
ActiveSheet.PasteSpecial Format:="HTML", Link:=False, DisplayAsIcon:= _
False, NoHTMLFormatting:=True
End Sub
2021.11.11 Bash 批量转utf-8
尝试使用了R的“lda”、“LDAvis”包做LDA模型。另,中文词典乱码可以在bash下使用enca包:
brew install enca
enca -L zh_CN -x utf-8 *
2021.8.14 Mysql M1芯片安装
按《MySQL详细安装教程》文章配置mysql,为了避免每次打开终端都要source,参考该文修改.bash_profile文件,新的Big sur11版本可修改.zshrc。
cd /usr/local/mysql/bin
./mysql
# ERROR 1045 (28000): Access denied for user 'yuteng'@'localhost' (using password: NO)`
按《Mac环境配置MySQL》一文,此时停止Mysql服务,在终端输入
cd /usr/local/mysql/bin/
sudo su #登录管理员权限
./mysqld_safe --skip-grant-tables & #禁止mysql验证功能,回车后mysql会自动重启
此时无法再通过设置内关闭mysql,如后续需开启验证或初始化mysql,可以参考《mac上系统偏好里无法停止mysql》一文杀死禁止进程或关闭mysql。
ps -ef | grep mysqld
sudo kill 14563 #14563是进程号pid 不同电脑不同
接上文,Mysql重启后,按以下步骤即可。以后打开终端可直接输入mysql -uroot -p123。
FLUSH PRIVILEGES
SET PASSWORD FOR ‘root’@‘localhost’ = PASSWORD(‘123’)
另可按ERROR 1045 (28000)解决办法修改密码。按《DB数据库文件转csv》转换db文件。
2021.8.11 Bash M1 npm
nvm:nodejs 版本管理工具。也就是说:一个 nvm 可以管理很多 node 版本和 npm 版本。
nodejs:在项目开发时的所需要的代码库
npm:nodejs包管理工具。在安装nodejs时,npm也会跟着一起安装,它是包管理工具。npm管理nodejs中的第三方插件。
按《MacOS下NVM的安装与使用》、《M1 nvm安装问题》两篇文章,在Sillicon M1下配置node.js。操作如下:
vim .zshrc #可替换为open .zshrc
source .zshrc
nvm install node
2021.8.10 Software M1虚拟机
换了M1 Macbook Air,按《M1 mac安装pd虚拟机升级win11》,配置了Win10系统。
六、日常生活中的统计学
2025.8.13 空间的历史
看到一张柏林的夜景卫星图,很好玩,可以看到明显城市的灯光颜色是分了两个区域的,东侧是偏暖的光线,西侧是偏冷的光线。这是因为当年东德和东柏林用的是钠灯作为路灯,而西德则用汞灯作为路灯。颜色冷暖不一样。柏林墙已经推倒了几十年,但两德分裂的历史竟然以这种方式仍然遗留着。
 Figure. 柏林夜景 ISS035-E-17210 2013.04.06
Figure. 柏林夜景 ISS035-E-17210 2013.04.062025.8.4 拟合的艺术
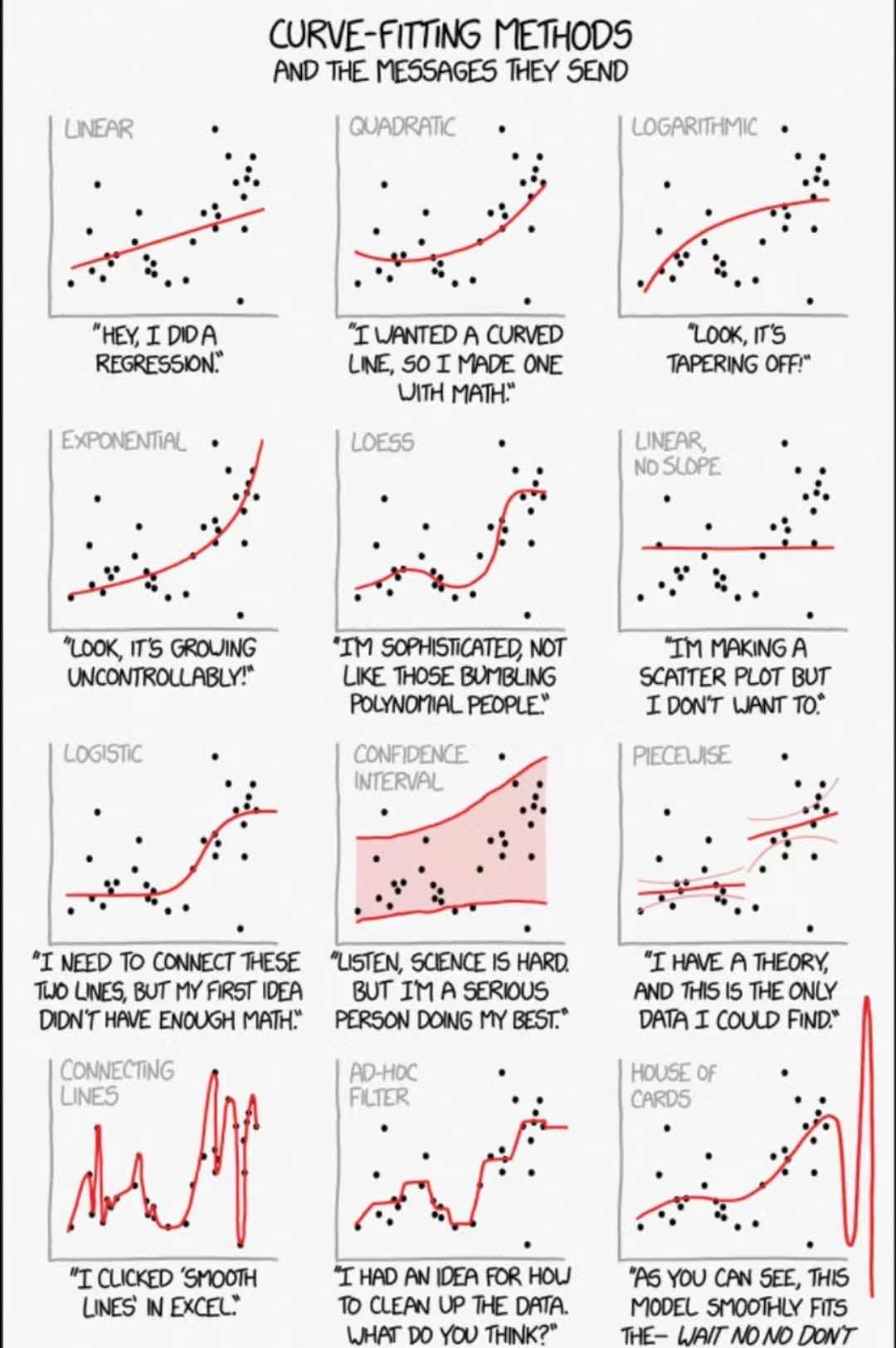
2025.8.3 健身房的正态分布
健身房的举重数据很符合正态分布,但更有趣的是从90直接跳到100,95出现了断点。这和人群身高很像,170、180会出现两个不自然的谎报峰值。健身房这里可能是“男人不能说不行”

2025.8.2 一类错误与二类错误
在这个context里面原假设H0是没怀孕/怀孕,备择假设H1是有怀孕。一型错误是rejecting the null hypo when it’s true = 拒绝患者没怀孕的事实,假阳;二型错误是accepting the null hypo when it’s fake = 接受患者没怀孕的错误信息,假阴。
此外,中国大陆学界的惯用语境是H0是有效果,H1是没有效果,这时可以理解type 1为弃真,type 2为存伪。另外如医学界会更重视避免一类错误,因一类错误意味着淘汰了原本正在使用的有效治疗。

2025.8.1 相关与因果
